The idea was suggested that sorting the input instance by variance might be beneficial to the running time of the algorithm. By placing the largest varied tasks first to be ordered more drastic differences in the lower bounds are noticed by the algorithm higher in the partial schedule tree. This noticing is reflected in larger sections of the tree becoming unnecessary to search earlier, and better best next selection.
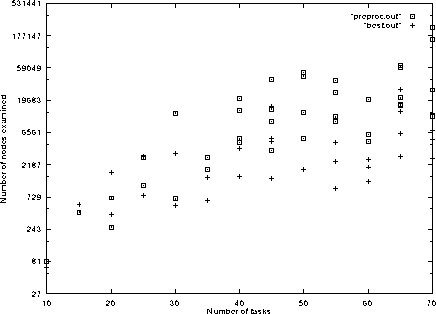
The above plot show a comparison between not preprocessing the input
instance and doing the processing. The program was run with several
different task list sizes, the horizontal axis, and measured the
number of nodes examined, the vertical axis. The boxes ( ![]() ) are the
number examined by the program without preprocessing and the pluses
(+) are the number examined by the program with preprocessing.
Generally, as you can see, the number examined is always lower for the
preprocessing program.
) are the
number examined by the program without preprocessing and the pluses
(+) are the number examined by the program with preprocessing.
Generally, as you can see, the number examined is always lower for the
preprocessing program.