For some years now, I have been working on a automatic hardware
based package recommendation system for Debian and other Linux
distributions. The isenkram system I started on back in 2013 now
consist of two subsystems, one locating firmware files using the
information provided by apt-file, and one matching hardware to
packages using information provided by AppStream. The former is very
similar to the mechanism implemented in debian-installer to pick the
right firmware packages to install. This post is about the latter
system. Thanks to steady progress and good help from both other
Debian and upstream developers, I am happy to report that
the Isenkram
system now are able to recommend 121 packages using information
provided via
AppStream.
The mapping is done using modalias information provided by the
kernel, the same information used by udev when creating device files,
and the kernel when deciding which kernel modules to load. To get all
the modalias identifiers relevant for your machine, you can run the
following command on the command line:
find /sys/devices -name modalias -print0 | xargs -0 sort -u
The modalias identifiers can look something like this:
acpi:PNP0000
cpu:type:x86,ven0000fam0006mod003F:feature:,0000,0001,0002,0003,0004,0005,0006,0007,0008,0009,000B,000C,000D,000E,000F,0010,0011,0013,0015,0016,0017,0018,0019,001A,001B,001C,001D,001F,002B,0034,003A,003B,003D,0068,006B,006C,006D,006F,0070,0072,0074,0075,0076,0078,0079,007C,0080,0081,0082,0083,0084,0085,0086,0087,0088,0089,008B,008C,008D,008E,008F,0091,0092,0093,0094,0095,0096,0097,0098,0099,009A,009B,009C,009D,009E,00C0,00C5,00E1,00E3,00EB,00ED,00F0,00F1,00F3,00F5,00F6,00F9,00FA,00FB,00FD,00FF,0100,0101,0102,0103,0111,0120,0121,0123,0125,0127,0128,0129,012A,012C,012D,0140,0160,0161,0165,016C,017B,01C0,01C1,01C2,01C4,01C5,01C6,01F9,024A,025A,025B,025C,025F,0282
dmi:bvnDellInc.:bvr2.18.1:bd08/14/2023:br2.18:svnDellInc.:pnPowerEdgeR730:pvr:rvnDellInc.:rn0H21J3:rvrA09:cvnDellInc.:ct23:cvr:skuSKU=NotProvided
pci:v00008086d00008D3Bsv00001028sd00000600bc07sc80i00
platform:serial8250
scsi:t-0x05
usb:v413CpA001d0000dc09dsc00dp00ic09isc00ip00in00
The entries above are a selection of the complete set available on
a Dell PowerEdge R730 machine I have access to, to give an idea about
the various styles of hardware identifiers presented in the modalias
format. When looking up relevant packages in a Debian Testing
installation on the same R730, I get this list of packages
proposed:
% sudo isenkram-lookup
firmware-bnx2x
firmware-nvidia-graphics
firmware-qlogic
megactl
wsl
%
The list consist of firmware packages requested by kernel modules,
as well packages with program to get the status from the RAID
controller and to maintain the LAN console. When the edac-utils
package providing tools to check the ECC RAM status will enter testing
in a few days, it will also show up as a proposal from isenkram. In
addition, once the mfiutil package we uploaded in October get past the
NEW processing, it will also propose a tool to configure the RAID
controller.
Another example is the trusty old Lenovo Thinkpad X230, which have
hardware handled by several packages in the archive. This is running
on Debian Stable:
% isenkram-lookup
beignet-opencl-icd
bluez
cheese
ethtool
firmware-iwlwifi
firmware-misc-nonfree
fprintd
fprintd-demo
gkrellm-thinkbat
hdapsd
libpam-fprintd
pidgin-blinklight
thinkfan
tlp
tp-smapi-dkms
tpb
%
Here there proposal consist of software to handle the camera,
bluetooth, network card, wifi card, GPU, fan, fingerprint reader and
acceleration sensor on the machine.
Here is the complete set of packages currently providing hardware
mapping via AppStream in Debian Unstable: air-quality-sensor,
alsa-firmware-loaders, antpm, array-info, avarice, avrdude,
bmusb-v4l2proxy, brltty, calibre, colorhug-client, concordance-common,
consolekit, dahdi-firmware-nonfree, dahdi-linux, edac-utils,
eegdev-plugins-free, ekeyd, elogind, firmware-amd-graphics,
firmware-ath9k-htc, firmware-atheros, firmware-b43-installer,
firmware-b43legacy-installer, firmware-bnx2, firmware-bnx2x,
firmware-brcm80211, firmware-carl9170, firmware-cavium,
firmware-intel-graphics, firmware-intel-misc, firmware-ipw2x00,
firmware-ivtv, firmware-iwlwifi, firmware-libertas,
firmware-linux-free, firmware-mediatek, firmware-misc-nonfree,
firmware-myricom, firmware-netronome, firmware-netxen,
firmware-nvidia-graphics, firmware-qcom-soc, firmware-qlogic,
firmware-realtek, firmware-ti-connectivity, fpga-icestorm, g810-led,
galileo, garmin-forerunner-tools, gkrellm-thinkbat, goldencheetah,
gpsman, gpstrans, gqrx-sdr, i8kutils, imsprog, ledger-wallets-udev,
libairspy0, libam7xxx0.1, libbladerf2, libgphoto2-6t64,
libhamlib-utils, libm2k0.9.0, libmirisdr4, libnxt, libopenxr1-monado,
libosmosdr0, librem5-flash-image, librtlsdr0, libticables2-8,
libx52pro0, libykpers-1-1, libyubikey-udev, limesuite,
linuxcnc-uspace, lomoco, madwimax, media-player-info, megactl, mixxx,
mkgmap, msi-keyboard, mu-editor, mustang-plug, nbc, nitrokey-app, nqc,
ola, openfpgaloader, openocd, openrazer-driver-dkms, pcmciautils,
pcscd, pidgin-blinklight, ponyprog, printer-driver-splix,
python-yubico-tools, python3-btchip, qlcplus, rosegarden, scdaemon,
sispmctl, solaar, spectools, sunxi-tools, t2n, thinkfan, tlp,
tp-smapi-dkms, trezor, tucnak, ubertooth, usbrelay, uuu, viking,
w1retap, wsl, xawtv, xinput-calibrator, xserver-xorg-input-wacom and
xtrx-dkms.
In addition to these, there are several
with
patches pending in the Debian bug tracking system, and even more
where no-one wrote patches yet. Good candiates for the latter are
packages
with
udev rules but no AppStream hardware information.
The isenkram system consist of two packages, isenkram-cli with the
command line tools, and isenkram with a GUI background process. The
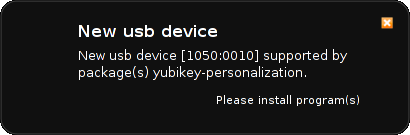
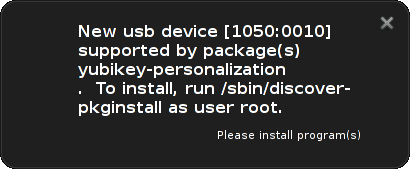
latter will listen for dbus events from udev emitted when new hardware
become available (like when inserting a USB dongle or discovering a
new bluetooth device), look up the modalias entry for this piece of
hardware in AppStream (and a hard coded list of mappings from isenkram
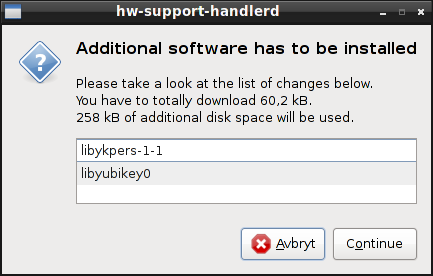
- currently working hard to move this list to AppStream), and pop up a
dialog proposing to install any not already installed packages
supporting this hardware. It work very well today when inserting the
LEGO Mindstorms RCX, NXT and EV3 controllers. :) If you want to make
sure more hardware related packages get recommended, please help out
fixing the remaining packages in Debian to provide AppStream metadata
with hardware mappings.
As usual, if you use Bitcoin and want to show your support of my
activities, please send Bitcoin donations to my address
15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.